
全部评论

谈谈您的想法...
京东JoyAI-VL-Interaction登顶视频理解模型趋势榜,视频AI进入“主动交互”时刻
2026-06-26 21:46:08 10秒看完全文要点
10秒看完全文要点
近日,京东开源的实时视频视觉语言交互模型 JoyAI-VL-Interaction 在 Hugging Face 社区获得关注,并登上 Hugging Face Trending 视频理解类第一。
这并不是一个普通的模型热度信号。它说明开发者正在寻找的,已经不只是“能看懂视频”的 AI,而是能够在连续视频流中主动判断、实时响应、持续交互的 AI。
从“你问我答”到“主动开口”
过去大多数视频 AI,本质上仍停留在“你问,它答”的阶段。用户不开口,模型就等待;即便接入摄像头,也更像一个会看画面的聊天框。
但真实世界里的很多关键时刻,并不会等待人类提问。老人跌倒时,不会先问一句“我有没有危险”;直播比赛进球时,不会等观众输入“刚才发生了什么”;屏幕上出现字幕时,也不应该要求用户每一帧都重新发送翻译指令。
这些场景需要的不是传统问答,而是一双全程在线、能够判断什么时候该开口的“眼睛”。JoyAI-VL-Interaction 试图解决的正是这个问题:让模型在连续的视频流中自主决定何时回应、何时沉默、何时把复杂任务交给后台 Agent。
换句话说,它不仅学会了什么时候该闭嘴,也学会了什么时候必须开口。
视频 AI 正在进入“流式交互”阶段
在看护场景中,老人正常活动时,模型可以保持沉默;一旦发现异常,则立即预警。
在实时翻译场景中,用户只需说一句“把字幕翻译成中文”,模型就会持续关注画面。每当新字幕出现,它会主动完成翻译,而不是翻完第一句后就停下来等待下一条指令。
这意味着视频 AI 正在从“轮次对话”走向“流式交互”。过去,交互节奏主要由用户控制;现在,“要不要开口”这个决定,开始交给模型自己。
对视频理解来说,实时性是绕不开的硬门槛。图片可以慢慢看,但视频中的很多事件都有窗口期。预警晚几秒,价值就会大幅下降;直播解说慢半拍,体验就不成立。
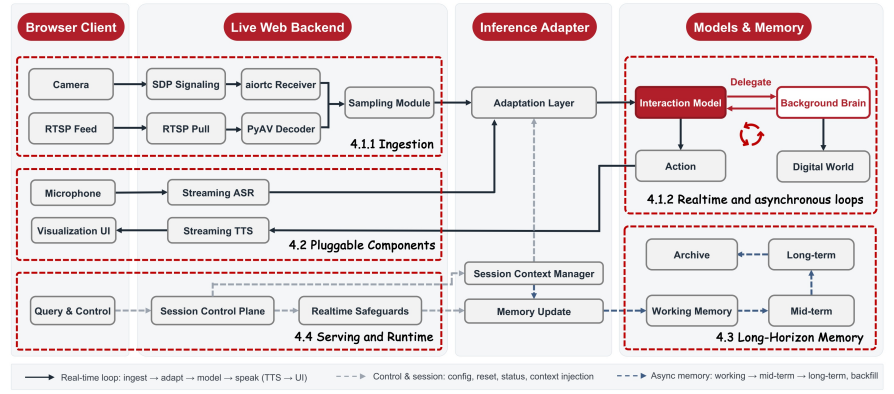
为了解决实时推理中的计算压力,JoyAI-VL-Interaction 引入了 AdaCodec:它并不对每一帧都投入完整视觉 token,而是在画面发生明显变化的关键帧上使用完整 token,在中间可预测帧上使用轻量 P-token。这样一来,计算量更接近随画面变化增长,而不是随着视频帧数线性爆炸。
同时,模型还采用了分层长程记忆机制:短期记忆保留最近的原始视觉信息,中期记忆保存文本摘要,长期记忆进一步压缩信息。多层记忆叠加后,可以覆盖约两小时上下文,并且压缩过程异步进行,不会阻塞实时推理。
在真实流式场景中验证能力
据京东披露的评测结果,JoyAI-VL-Interaction 覆盖了监控预警、实时计数、实时翻译、时间感知、直播导览解说等真实流式场景。
在 58 个真人盲评案例中,JoyAI-VL-Interaction 对比豆包视频通话助手的总体胜率为 77.6%,对比 Gemini 视频通话助手的总体胜率为 87.9%。其中,在监控预警场景中,JoyAI-VL-Interaction 对两个基线均取得 100% 胜率。
以摔倒检测为例,该模型可以在人倒下的瞬间触发提醒,体现出主动交互模型在安全类场景中的价值。对于这类应用而言,关键不只是识别是否准确,更在于能否在正确时间响应。它的优势不只在于“答得对”,更在于“来得及”和“跟得住”。
另一个值得关注的能力,是任务委派。当模型遇到数学推导、网页复刻、代码生成等复杂任务时,可以将任务交给后台大模型或 Agent 处理,自己则继续保持前台视频交互。
前台负责持续观察真实世界,后台负责处理复杂任务;等结果返回后,再自然接回对话。这让 JoyAI-VL-Interaction 不再只是一个视频问答助手,而更像一套“前台实时陪伴 + 后台任务执行”的协作系统。
开源的不只是模型权重,而是一套系统
也正因此,JoyAI-VL-Interaction 在 Hugging Face 上获得高下载量并不意外。开发者真正需要的,不只是论文中的能力展示,而是能跑起来、改得动、接得进业务系统的东西。
京东此次开源的也不是孤立权重,而是包括训练 recipe、超过 400 万条时间对齐交互数据,以及完整可部署系统。ASR/TTS 语音模块、三层长程记忆、可视化操作界面、后台 Agent 桥接等模块,也都以可插拔方式开放。
过去很多开源多模态模型,只提供权重和推理代码。真正落地时,视频流接入、推理优化、语音输入输出、会话状态管理、Agent 调度等工程环节,仍然需要开发者自己补齐。JoyAI-VL-Interaction 的价值在于,它把模型能力和系统能力一起放了出来。
从视频问答走向视频交互
从更大的趋势看,多模态 AI 正在从图文理解,走向视频、语音、动作和环境交互。
图片问答解决的是“看见什么”,视频理解要解决的是“发生了什么”,而 JoyAI-VL-Interaction 进一步尝试回答的是:“什么时候该回应,以及接下来该做什么”。这一步很关键。
因为真实世界不是静态截图,而是连续流动的。直播、电商、物流、仓储、安防、客服、教育、陪伴、具身智能等场景,都需要 AI 持续在场,而不是被动等待问题。
JoyAI-VL-Interaction 在 Hugging Face 视频理解类模型下载榜登顶,某种程度上说明,开源社区正在把注意力从“视频问答”转向“视频交互”。
当 AI 不再只是等人提问,而是能够持续观察、主动判断、适时开口,并把复杂任务交给后台执行时,视频 AI 的产品形态也许会被重新定义。JoyAI-VL-Interaction 的走热,可能只是这个变化的开始。